Chrome DevTools:在 Profile 性能分析中显示原生 javascript 函数
在 Chrome DevTools 中可以使用 profiler 查看原生函数的执行性能:
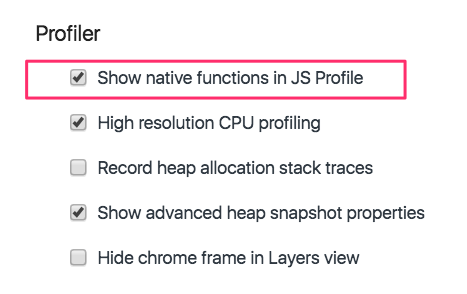
原生函数(native function)是 JavaScript 语言的一部分,这些函数有别于开发者编写的自定义函数。当我们在 profiler 中查看代码的调用栈时,这些函数是被过滤掉的。我们在 profiler 中看到的只有自己写的代码。
当我们捕获调用栈时,Chrome 并不会捕获 C++ 写的函数。不过,在 V8 引擎中很多 javascript 原生函数都是使用 javascript 语言编写的。
V8 使用 JavaScript 本身实现了 JavaScript 语言的大部分内置对象和函数。 例如,promise 功能就是通过 JavaScript 编写的。我们把这样的内置函数称为自主托管(self-hosted)。
如果我们开启 “Show native functions” 设置,Chrome 将会在 profiler 中显示这些函数。
Chrome 分析器是如何工作的
为了找到那些耗时最多的代码,Chrome 分析器每 100μs 捕获一个堆栈跟踪。
这意味着,如果一个函数只需要 50μs 的执行时间,就可能不会在分析器中显示出来!
当你分析几毫秒以上的时间时,可以准确了解应用程序在何时花费最多的时间。 但是,当你放大 profiler 面板想看更精准的时间时,信息会变得不太准确。
分析器也会不一致。 每次运行时,会产生一个稍微不同的结果。 有时可能会记录非常短的函数调用,而在其他时间再次运行这些函数调用信息可能会丢失。
通过这篇博客文章我将为大家演示如何捕获并分析原生函数的性能。当你自己运行代码时,结果可能会有所不同。
Array.join
首先,我们运行如下代码:
var arr = []for (var i=0; i<1000; i++){ arr.push(i)}console.profile("Array.join")arr.join(",")console.profileEnd("Array.join")选择 profiler 的 “Chart” 视图:
第一次分析时,我们不选中 “Show native functions”:

我们再次运行时,把 “Show native functions” 启用:

当我们把鼠标指向函数时,会看到更加详细的信息:
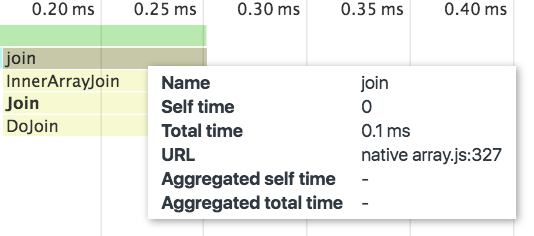
如上信息中,chrome devtools 展示了原生函数的行号,你可以在 Chrome code search中找到这个文件 “array.js”。行号信息可能不同,因为 V8 源码的最新版本和 Chrome 使用的 V8 版本可能不一样。
你可以看到 ArrayJoin 函数在内部调用了 InnerArrayJoin:
function ArrayJoin(separator) { CHECK_OBJECT_COERCIBLE(this, "Array.prototype.join"); var array = TO_OBJECT(this); var length = TO_LENGTH(array.length); return InnerArrayJoin(separator, array, length);}InnerArrayJoin 在内部调用了 DoJoin。
DoJoin 调用了 %StringBuilderJoin。
%StringBuilderJoin 是使用 C++ 实现的。
稀疏数组
我们有点偏离主题,但是我认为 V8 处理稀疏数组(new Array(n))是非常有趣的。

为什么这很有用呢?
下面的代码是如何运行的?
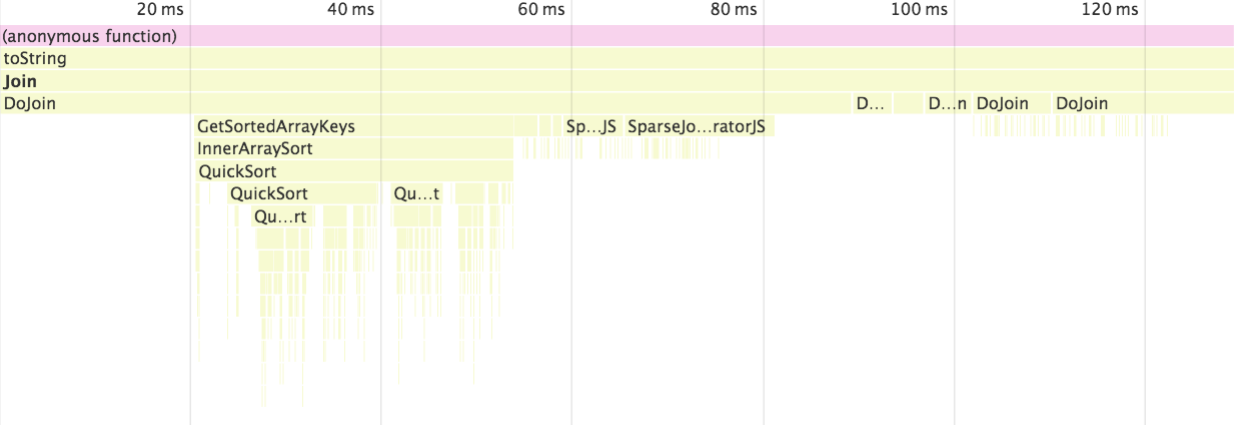
arr = new Array(10000000)for (var i=0; i<10000; i++){ arr.push(i)}console.profile("arr + arr")arr + arrconsole.profileEnd("arr + arr")您通常不会在两个数组上执行加操作。但是由于某种原因,我最近看过的一些代码就是这样做的。
当不是用查看原生函数时,我们看到了一个匿名函数的调用。

当我们开启了查看原生函数功能时,Chrome 调用了 array 的 toString 方法,然后调用了 join 方法。
Error().stack
我们来看一个不同的例子。在 JavaScript 中,您可以使用 Error().stack 获取当前正在运行的函数的堆栈跟踪(stack trace)。
当我们运行该代码时,一共做了两件事: 首先我们创建一个新的 Error 对象,然后访问它的 stack 属性。

获取堆栈跟踪的字符串描述信息时,耗费了大量的时间。
我能够通过获取一个 Error 对象来加快我正在处理的代码:只有当我需要显示堆栈跟踪时,才解析其 stack 属性。
不准确的地方
在我的文章的开头章节,我提到了非常小的时间间隔可能造成结果的不准确。为了说明这一点,我在另一台不同配置的电脑上运行了 Error().stack 的代码段。
我们看到了 FormatErrorString 函数,而在之前的分析中,这个函数并没有显示出来。
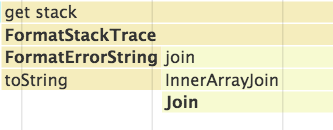
(这次的总执行时间是 ~1ms,这意味着 Chrome 需要 10 个调用堆栈的样本。上面的例子花了 ~10ms,因为我在循环中调用了 10 次 Error().stack。)